
こんにちは、トイロジックでツール業務を担当しているプログラマーのIです。主にプロジェクトで使用するGUI/CUIツールやDCCツールの作成・整備を行っています。
本記事は、以前投稿したブログの続きとなります。
今回はコード生成部分の高速化と、開発効率の向上のために行った対応に関してご紹介できればと思います。
目次
コード生成に関して
コード生成に関しては以前にもブログ(【ツール・初級】 社内ShaderEditorでノードからHLSLを自動生成するには」)でご紹介したことがあります。
基本的なコード生成のための手法はこの頃と変わりません。
出力ノードの各ソケットから繋がりをたどっていき、その都度繋がっている先のノードをリストの先頭に積んでいく(既にリスト内にある場合は先頭に移動する)ことで、ノード同士の依存が考慮された並びになります。この並び替えられたリストの先頭からコードを生成していくわけです。
このようにして高速化を行った
ノードの依存順の並び替えにList<T>を使用しない
これは、「List<T>(※1)」の内部実装に関して知っていれば当たり前の話ではあったのですが、旧ShaderEditorではList<T>を使用して並び替えを行ってしまっていました。
なぜダメなのかというと、List<T>は内部的にはTの配列を保持しており、リストのキャパシティを超えた場合、配列の拡張(アロケート)が行われる、また、List<T>での位置の入れ替え(Remove/Insert)はそのたびに配列のメモリコピーが走ります。
簡単に言うと頻繁に要素の入れ替えが行われる場合にList<T>は向かないんですね。
こういう時は「LinkedList<T>(※2)」を使いましょう。
List<T>は「動的配列」として実装されているのに対して、LinkedList<T>は「連結リスト」として実装されています。
LinkedList<T>内部では、各要素はLinkedListNode<T>とうノードで管理されており、各ノード同士が「Previous」と「Next」によって繋がります。
これにより、順番の入れ替えは「Previous」と「Next」を繋ぎなおしだけで終わります。
頻繁に要素の入れ替えが発生する場合は、圧倒的にこちらを使用する方が速いです。
List<T>の利点はインデックスアクセスができるのと、内部的には配列なので要素を回す際には速いですが、今回の場合並び替えのコストの方が圧倒的に大きいのでLinkedList<T>を使用するのがベストです。
これだけで、1000ノード以上ある場合でも、数分かかっていた並び替えが数秒で終わるようになります。
ブログでは1000ノード以上と表現していますが、これは見えているノードの数だけで、実際には「ユーザー関数 ※1」が存在する場合、その中に存在で定義されているノードも処理する必要があるためその分ノード数は増えていきます。
LinkedList<T>からもっと高速化する
さて、LinkedList<T>を使用することで高速化に繋がりましたが、まだ問題があります。それは、リスト内に要素が存在するかどうかの確認とそのノードの検索です。
LinkedList<T>は要素を検索する際、HeadからNextをたどって要素を見つける必要があります。いわゆる線形探索です。
要素の数が少ない場合はそれほどコストはありませんが、要素の数が増えるにつれて検索のコストが上がっていきます。
1000ノードほどあって、依存順の並び替えで100万回ほど要素の検索が発生する場合、このコストは大きくなります。
そこで目を付けたのは、C#の「Dictionary<TKey, TValue>」や「HashSet<T>」などでも内部的に使用されているハッシュテーブルです。
このハッシュテーブルは「バケット(bucket)」とい概念が重要な役割を果たしています。
簡単に表現すると、特定の数のバケツを最初に用意し、要素のGetHashCode()により得たハッシュコードを要素の数内に圧縮し、該当するインデックスのバケツに詰めます。
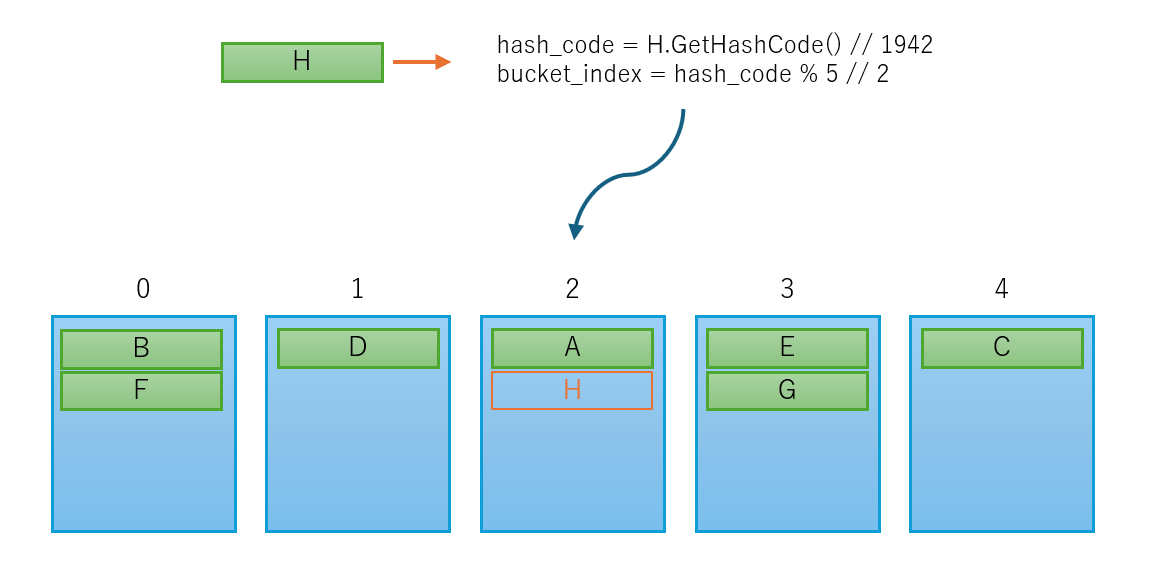
この場合、検索する際はまずハッシュコードから含まれている可能性のあるバケツのインデックスを特定し、そのバケツ内の要素からハッシュコード比較を行い検索します。
Dictionary<TKey, TValue>やHashSet<T>の場合、内部実装として以下のような実装になっています。
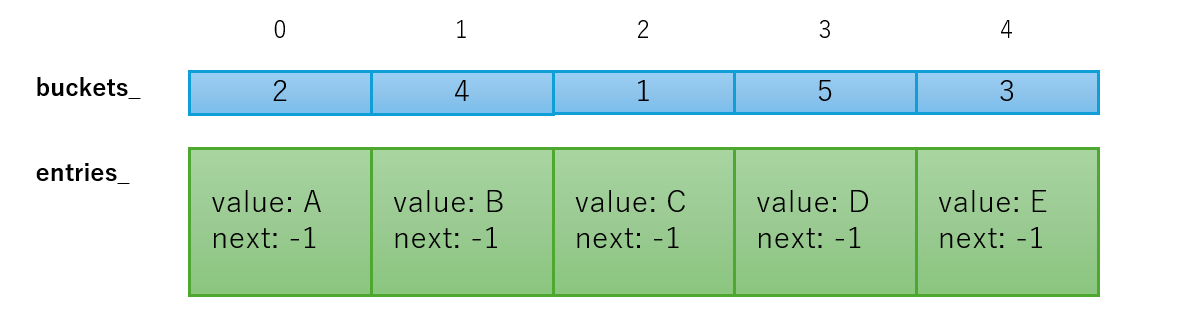
このように「buckets_」と「entries_」という配列が確保されており、「entires_」には要素を追加した順番で要素と、同じバケツに所属する次のエントリーへのインデックスを保持します。
「buckets_」はハッシュコードから計算したバケツのインデックスにエントリーへのインデックスを +1 して格納します。(0が無効値となる)
要素を検索する際は、ハッシュコードから「buckets_」のインデックスを計算し、「buckets_」に格納されている「entries_」へのインデックスの値を取得、0である場合はまだエントリーが存在しない、1 以上である場合はその値に -1 を行い「entries_」の要素を取得します。
エントリーに格納されている値のハッシュコードで比較を行い、同じでなければ次のエントリーで比較を繰り返し要素を検索します。
エントリーが持つ要素はDictionary<TKey, TValue>やHashSet<T>によて異なります。
デメリットとしては、メモリ使用量が多くなったり、コードが肥大化しやすい、ハッシュコード計算のコストなどありますが、検索の速さは圧倒的です。
今回はこのハッシュテーブルの仕組みを使用して LinkedList<T> の拡張を行いました。
/// <summary>
/// 最大サイズが固定された一意な値を先頭に追加する連結リストを表します.
/// </summary>
/// <remarks>
/// 基本的に削除はできず、先頭への追加(既に含まれる場合は先頭へ移動)のみが可能です.<br/>
/// 最初に確保したサイズ以上の要素を追加しようとした場合、例外が発生します.
/// </remarks>
/// <typeparam name="T">リストの要素の型.</typeparam>
public class FixedSizeRecentSet<T> : IEnumerable<T>
{
private readonly int _maxSize;
private readonly int[] _buckets;
private readonly Entry[] _entries;
private readonly ulong _fastModMultiplier;
internal FixedSizeRecentSetNode<T>? _head;
private int _count;
private int _version;
/// <summary>
/// 最大サイズ.
/// </summary>
public int MaxSize => _maxSize;
/// <summary>
/// リスト内の要素の数.
/// </summary>
public int Count => _count;
/// <summary>
/// 先頭のノード.
/// </summary>
public FixedSizeRecentSetNode<T>? Head => _head;
/// <summary>
/// 末尾のノード.
/// </summary>
public FixedSizeRecentSetNode<T>? Tail => _head?._prev;
/// <summary>
/// 初期化します.
/// </summary>
/// <param name="maxSize">最大サイズ.</param>
public FixedSizeRecentSet(int maxSize)
{
var size = HashHelper.GetPrime(maxSize);
_maxSize = maxSize;
_buckets = new int[size];
_entries = new Entry[size];
_fastModMultiplier = HashHelper.GetFastModMultiplier((uint)size);
}
/// <summary>
/// 先頭に要素を追加します.
/// </summary>
/// <param name="item">追加する要素.</param>
/// <returns>生成されたノードが返ります.</returns>
public FixedSizeRecentSetNode<T> AddHead(T item)
{
var node = FindNode(item);
if (node is null)
{
node = Allocate();
node._list = this;
node._item = item;
TryEntryInsert(node);
}
if (_head is null)
{
InternalInsertNodeToEmptyList(node);
}
else
{
InternalRemoveNode(node);
InternalInsertNodeBefore(_head, node);
_head = node;
}
return node;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void InternalInsertNodeToEmptyList(FixedSizeRecentSetNode<T> node)
{
node._next = node;
node._prev = node;
_head = node;
_version++;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void InternalInsertNodeBefore(FixedSizeRecentSetNode<T> point, FixedSizeRecentSetNode<T> node)
{
node._next = point;
node._prev = point._prev;
point._prev!._next = node;
point._prev = node;
_version++;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private void InternalRemoveNode(FixedSizeRecentSetNode<T> node)
{
if (node._next is null &&
node._prev is null)
return;
if (node._next == node)
{
_head = null;
}
else
{
node._next!._prev = node._prev;
node._prev!._next = node._next;
if (_head == node)
_head = node._next;
}
node._next = null;
node._prev = null;
_version++;
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private ref int GetBucket(uint hashCode)
{
var buckets = _buckets;
return ref buckets[HashHelper.FastMod(hashCode, (uint)buckets.Length, _fastModMultiplier)];
}
/// <summary>
/// 指定したノードをエントリーに追加します.
/// </summary>
/// <param name="node">追加するノード.</param>
/// <returns>エントリーへの登録が行われた場合は true、それ以外は false が返ります.</returns>
private bool TryEntryInsert(FixedSizeRecentSetNode<T> node)
{
var entries = _entries;
var c = EqualityComparer<T>.Default;
var hashCode = (uint)c.GetHashCode(node._item!);
var collisionCount = 0u;
ref var bucket = ref GetBucket(hashCode);
var i = bucket - 1;
while ((uint)i < (uint)entries.Length)
{
if (entries[i].HashCode == hashCode && c.Equals(entries[i].Node!._item, node._item))
{
return false;
}
i = entries[i].Next;
++collisionCount;
if (collisionCount > (uint)entries.Length)
{
return false;
}
}
var index = _count;
_count = index + 1;
if ((uint)index == (uint)entries.Length)
{
return false;
}
ref var entry = ref entries[index];
entry.HashCode = hashCode;
entry.Next = bucket - 1;
entry.Node = node;
bucket = index + 1;
return true;
}
/// <summary>
/// ノードを生成します.
/// </summary>
/// <returns>生成したノードのインスタンスが返ります.</returns>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
private FixedSizeRecentSetNode<T> Allocate()
{
if (_count == _maxSize)
throw new InvalidOperationException("Cannot allocate more than the maximum size.");
return new FixedSizeRecentSetNode<T>();
}
/// <summary>
/// 指定した要素のノードを検索します.
/// </summary>
/// <param name="item">検索する要素.</param>
/// <returns>要素のノードが見つかった場合はそのインスタンス、それ以外は null が返ります.</returns>
private FixedSizeRecentSetNode<T>? FindNode(T item)
{
var entries = _entries;
var c = EqualityComparer<T>.Default;
var hashCode = (uint)c.GetHashCode(item!);
ref var bucket = ref GetBucket(hashCode);
var i = bucket - 1;
var collisionCount = 0u;
do
{
if ((uint)i >= (uint)entries.Length)
{
break;
}
ref var entry = ref entries[i];
if (entry.HashCode == hashCode && c.Equals(entry.Node!._item, item))
{
return entry.Node;
}
i = entry.Next;
++collisionCount;
} while (collisionCount <= (uint)entries.Length);
return null;
}
/// <summary>
/// コレクションを反復処理する列挙子を返します.
/// </summary>
/// <returns>コレクションの反復処理に使用できる列挙子が返ります.</returns>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public IEnumerator<T> GetEnumerator()
{
return new Enumerator(this);
}
/// <summary>
/// コレクションを反復処理する列挙子を返します.
/// </summary>
/// <returns>コレクションの反復処理に使用できる列挙子が返ります.</returns>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
private struct Entry
{
public int Next;
public uint HashCode;
public FixedSizeRecentSetNode<T>? Node;
}
internal struct Enumerator : IEnumerator<T>
{
private readonly FixedSizeRecentSet<T> _list;
private readonly int _version;
private FixedSizeRecentSetNode<T>? _node;
private T? _current;
private int _index;
public T Current => _current!;
object? IEnumerator.Current
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
get
{
if (_index == 0 || _index == _list._count + 1)
{
throw new InvalidOperationException("Enumeration has either not started or has already finished.");
}
return Current;
}
}
internal Enumerator(FixedSizeRecentSet<T> list)
{
_list = list;
_version = list._version;
_node = list._head;
_current = default;
_index = 0;
}
public bool MoveNext()
{
if (_version != _list._version)
{
throw new InvalidOperationException("Collection was modified after the enumerator was instantiated.");
}
if (_node is null)
{
_index = _list._count + 1;
return false;
}
++_index;
_current = _node._item;
_node = _node._next;
if (_node == _list._head)
{
_node = null;
}
return true;
}
public void Reset()
{
if (_version != _list._version)
{
throw new InvalidOperationException("Collection was modified after the enumerator was instantiated.");
}
_current = default;
_node = _list._head;
_index = 0;
}
public void Dispose()
{
}
}
}
/// <summary>
/// 最大サイズが固定された一意な値を先頭に追加する連結リストのノードを表します.
/// </summary>
/// <typeparam name="T">リストの要素の型.</typeparam>
public sealed class FixedSizeRecentSetNode<T>
{
internal T? _item;
internal FixedSizeRecentSetNode<T>? _next;
internal FixedSizeRecentSetNode<T>? _prev;
internal FixedSizeRecentSet<T>? _list;
/// <summary>
/// このノードの要素.
/// </summary>
public T? Value
{
get => _item;
set => _item = value;
}
/// <summary>
/// 次のノード.
/// </summary>
public FixedSizeRecentSetNode<T>? Next => _next is null || _next == _list!._head ? null : _next;
/// <summary>
/// 前のノード.
/// </summary>
public FixedSizeRecentSetNode<T>? Previous => _prev is null || this == _list!._head ? null : _prev;
/// <summary>
/// 属するリスト.
/// </summary>
public FixedSizeRecentSet<T> List => _list!;
}
/// <summary>
/// ハッシュに関するヘルパークラスを提供します.
/// </summary>
public static class HashHelper
{
internal const int HashPrime = 101;
internal static ReadOnlySpan<int> Primes =>
[
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369
];
/// <summary>
/// 指定した値が素数かどうかを判定します.
/// </summary>
/// <param name="candidate">候補となる値.</param>
/// <returns>素数である場合は true、そうでない場合は false が返ります.</returns>
public static bool IsPrime(int candidate)
{
if ((candidate & 1) == 0)
return candidate == 2;
var limit = (int)Math.Sqrt(candidate);
for (var divisor = 3; divisor <= limit; divisor += 2)
{
if ((candidate % divisor) == 0)
return false;
}
return true;
}
/// <summary>
/// 指定した値以上の最小の素数を返します.
/// </summary>
/// <param name="min">最小の値.</param>
/// <returns>最小の素数が返ります.</returns>
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException("Hashtable's capacity overflowed and went negative. Check load factor, capacity and the current size of the table.");
foreach (ref readonly var prime in Primes)
{
if (prime >= min)
return prime;
}
for (var i = (min | 1); i < int.MaxValue; i += 2)
{
if (IsPrime(i) && ((i - 1) % HashPrime != 0))
return i;
}
return min;
}
/// <summary>
/// 除数の近似逆数を返します: ceil(2**64 / 除数).
/// </summary>
/// <param name="divisor">除数.</param>
/// <returns>除数の近似逆数が返ります.</returns>
public static ulong GetFastModMultiplier(uint divisor) => ulong.MaxValue / divisor + 1;
/// <summary>
/// <see cref="GetFastModMultiplier"/> で事前に計算された乗数を使用して mod 演算を実行します.
/// </summary>
/// <param name="value">値.</param>
/// <param name="divisor">除数.</param>
/// <param name="multiplier">除数の近似逆数.</param>
/// <returns>mod 演算の結果が返ります.</returns>
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static uint FastMod(uint value, uint divisor, ulong multiplier)
{
Debug.Assert(divisor <= int.MaxValue);
var highBits = (uint)(((((multiplier * value) >> 32) + 1) * divisor) >> 32);
Debug.Assert(highBits == value % divisor);
return highBits;
}
}
これは、サイズ固定されたものですが、実際にはサイズ可変のものを使用しています。
HashHelper.csに関して、コレクションのバッファの拡張を行う際は、基本必要なサイズより大きいサイズで再確保を行います。そのため、必要なサイズ以上の素数を探し、それを次のキャパシティとして使用しています。これらは、.NETの実装を参考にしています。ノードの依存順の並び替えに関しては、これを使用することでかなりの高速化が行えました。
バリエーション/シェーダー プロファイルごとに依存順の並び替えを行わない
弊社のマテリアルでは、バリエーションによる分岐を行うことができます。
バリエーション/シェーダー プロファイルによってコード生成に使用されるノードが異なるため、旧ShaderEditorでは、バリエーション/シェーダー プロファイルごとに依存順に並び替えたリストを作成していました。
そうです。コストのかかる並び替えを何回も行っていたんですね。
今回は高速化のために、 依存順の並び替え自体は1回のみにして、コード生成時に生成の必要のあるノードなのかを判断するようにしました。
単純ですが、これだけでも高速化に繋がります。
開発効率向上のための対応
私は従来よりノードベースでのマテリアル作成の全体の把握しづらさの問題について考えていました。
例えば、コードがどのノードを使用して生成されているのか、特定のノードがどこに配置されているのかなど。
ノードの数が少なければ問題ありませんが、数が多くなればなるほど把握が難しくなります。
そのため、コメントノードを用意してこのノードが何を意味しているのかをメモできるようにしたり
スパゲッティーノードを避けるためのワイヤレスノード (Unreal EngineでのNamed Reroute Node ※1) を用意したり
など行っていましたが、それでもまだ把握しづらい問題は残っていました。
これに伴い、今回のShaderEditorの改修にあたって入れてみた対応を少しご紹介しようと思います。
コメントバブル
コメントノードだけではなく、ノード自体にもコメントを付けれるように対応しました。
生成コードからノードの選択
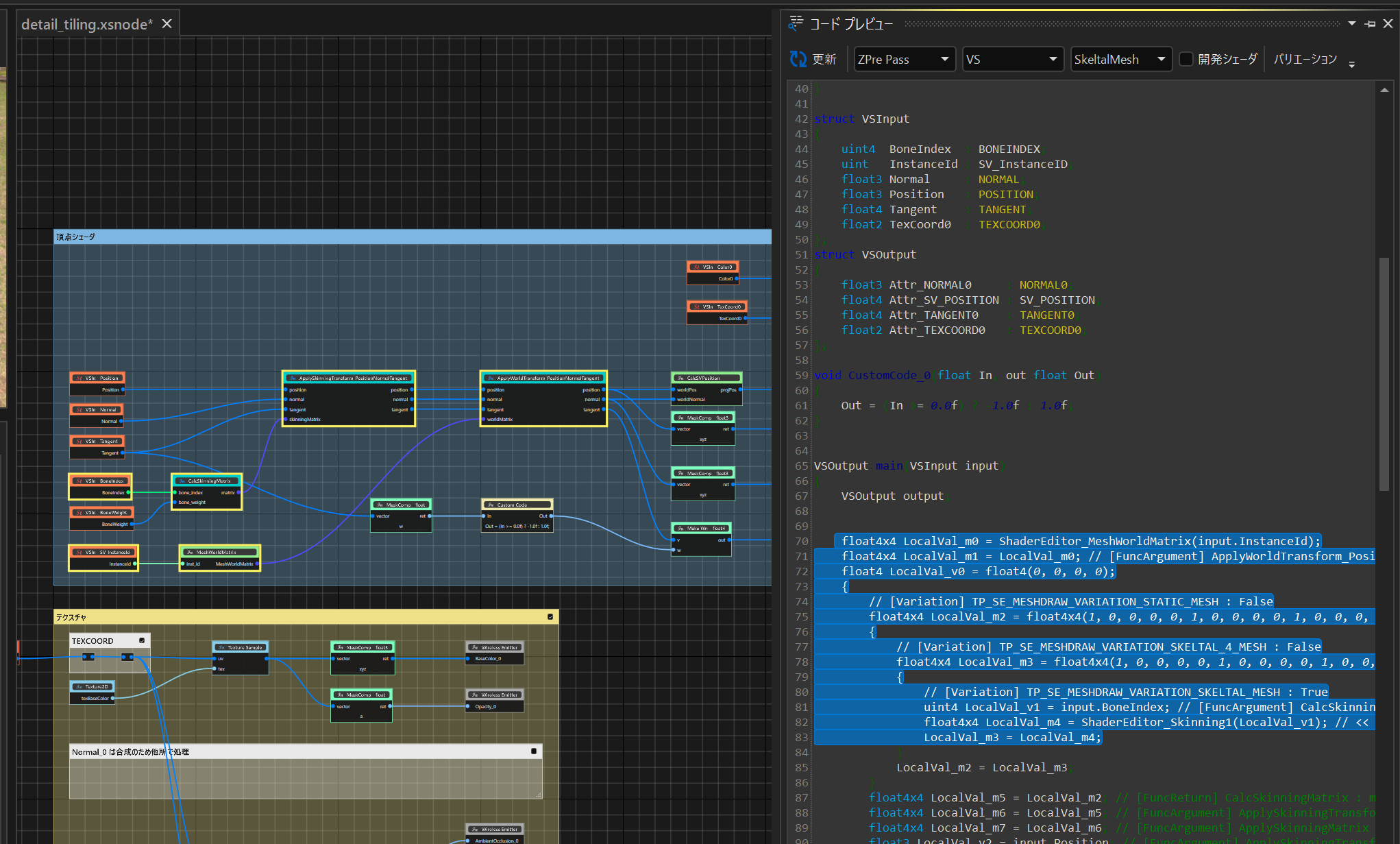
ShaderEditorでは、生成コードのプレビューを行うことができます。プレビュー上のコードで範囲選択を行うと、その範囲のコードの生成に使用されたノードがリアルタイムにノードグラフ上で選択されるように対応しました。
これによって、そのコードがどのノードによって生成されたのかが把握しやすくなります。
旧ShaderEditorでは、逆のノード選択時にコードプレビュー側にマーキングも対応していました。
これも今後入れたいと思っています。
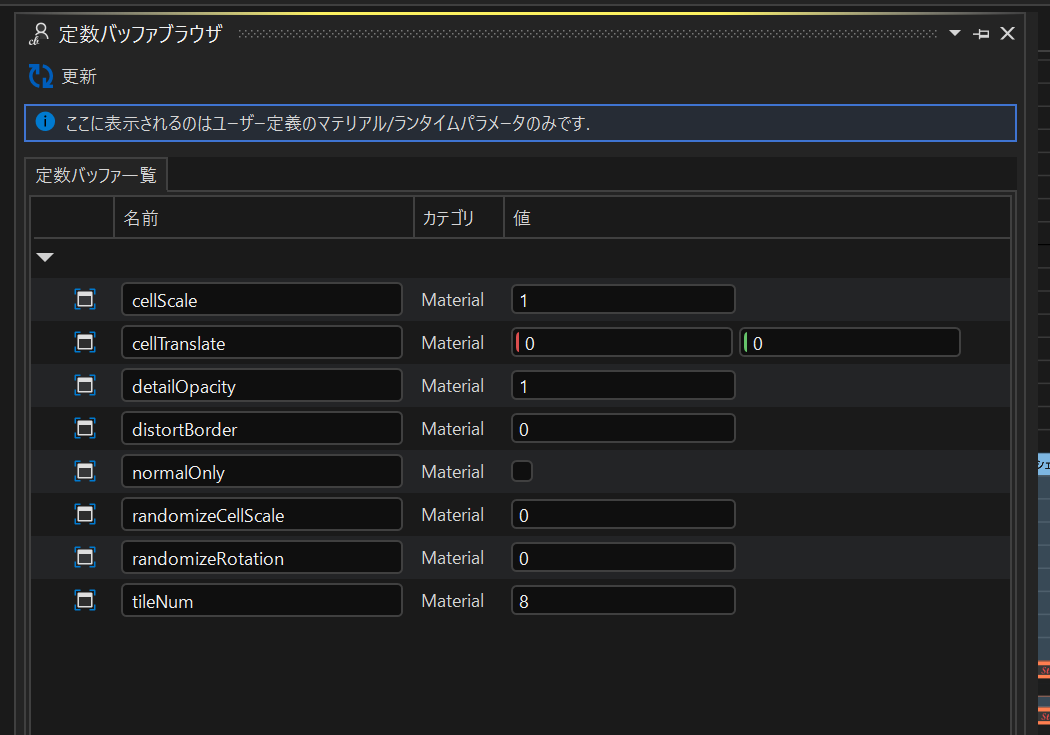
定数バッファのパラメータ一覧表示
ノードによって生成された定数バッファのパラメータを一覧で確認できるようにしました。ここから定数バッファのパラメータ名や、デフォルト値を編集したり、パラメータノードのフォーカスを行うことができます。
ワイヤレスノードの繋がりの可視化
ワイヤレスノードにはスパゲッティーノードを避けるという利点もありますが、いろんな個所に分散されている場合、どこと繋がっているのかがわからなくなるという問題がありました。
ノード数が多くなるほどに、どこと繋がっているかがほぼ把握できません。
エミッター/レシーバーノードに共通のカラーを設定できるようになども行いましたが、ノードグラフを引いてみると色の違いなんか分からなくなりますよね。
そこで、エミッター/レシーバーノードを選択した場合のみ、そのノードがつながるノードまでリンクを可視化するようにしました。
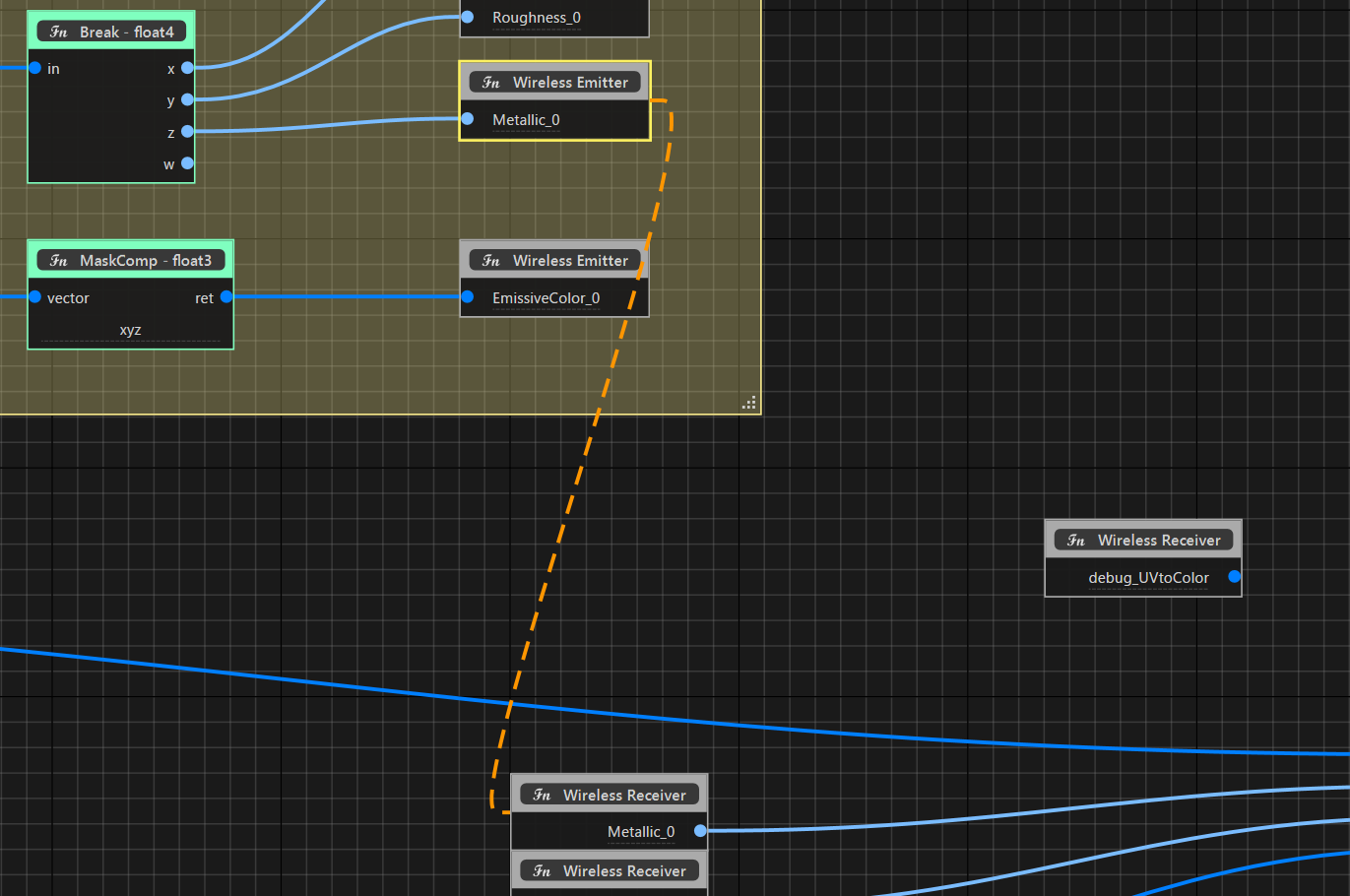
これが入るだけで、繋がりを追うのが劇的に楽になります。
これはかなり効果のある対応だと思います。
ワイヤレスノード同士の検索
先のどの繋がりの可視化以外にも、エミッターノード ⇔ レシーバーノードの検索を行えるようにしました。
レシーバーノードからはエミッターノードへのジャンプ、エミッターノードからは参照されているレシーバーノードの一覧の表示が行えるようにしました。
ノードの検索
今まで対応できていなかったものとして、ノードの検索機能を用意しました。
これにより、探しているノードへすぐにアクセスすることができます。
あいまい検索
追加するノードを選ぶ際のフィルタリングや、ノード検索時のフィルタリングなど、様々な個所であいまい検索のアルゴリズムを使用しています。
私は「FuzzySharp (※1)」というオープンソースを使用しています。
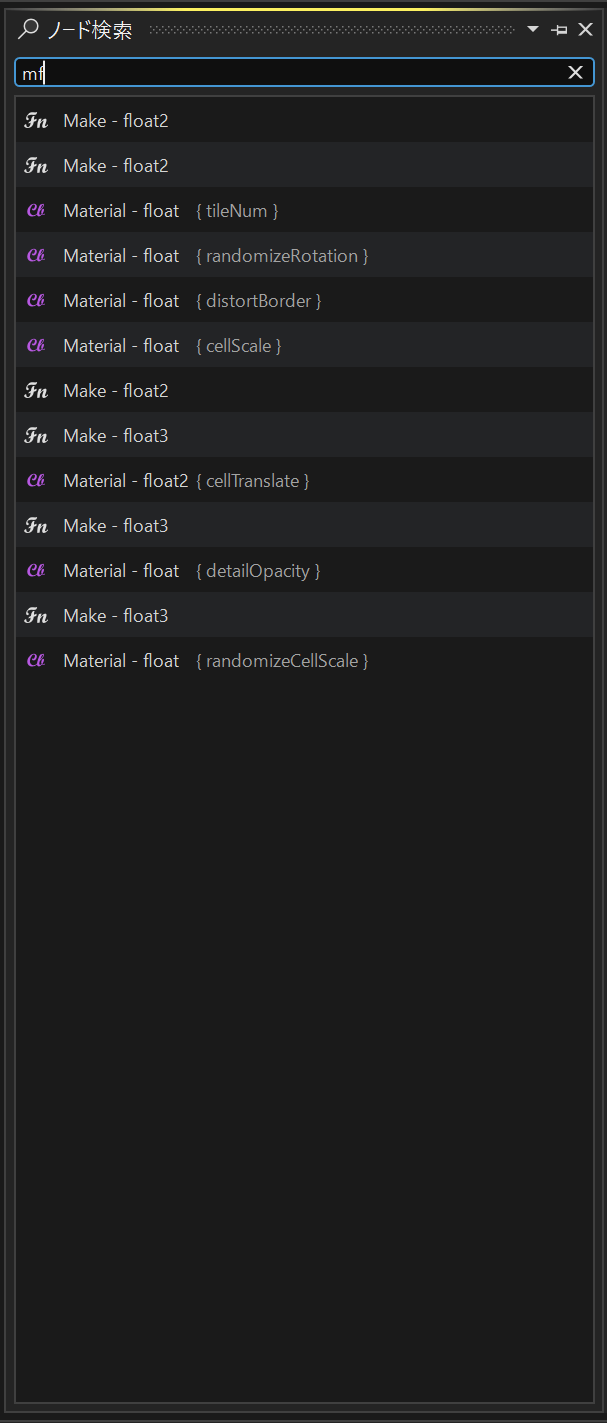
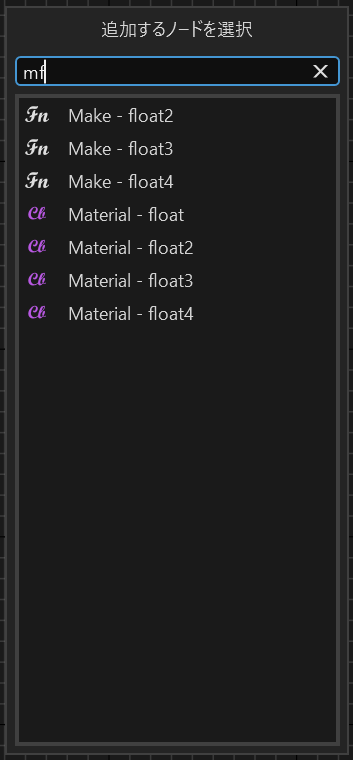
こういったフィルタリングに使用する場合
Fuzz.PartialRatio
を使用するのがいいのではないかなと思います。
私の場合はこれだけでは求めていたあいまい検索の結果を満たせなかったので、少しスコア計算をカスタマイズして使用しています。
最後に
いかがでしたでしょうか? これ以外にも、弊社ShaderEditorでは、ノードの繋がりからほぼリアルタイムにソケットの型の特定を行いノードに反映、キャストできない型への接続は行えないようになども行っています。
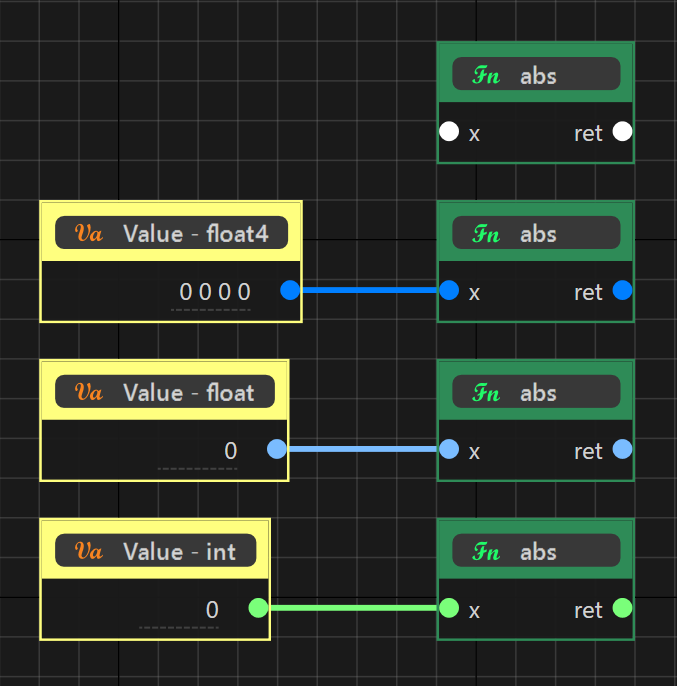
このような型の決定フローや、前のブログでも話に出ていた「ユーザー関数」など、今回紹介したところ以外にも高速化を行っています。地道に高速化を行っていったおかけで、以前より開発しやすいツールになっているのではないかなと思います。
今回ご紹介した内容は、そんなの当たり前にやってるよ!という方もいるかと思いますが、少しでも参考になっていれば幸いです。
まだ「その1」を見ていないという方は、ご興味があれば見ていただけると嬉しいです。